Project — The Search for an ideal home in Helsinki area
Table of contents
* [Introduction: Business Problem]
* [Data]
* [Methodology]
* [Analysis]
* [Results and Discussion]
* [Conclusion]
A. Introduction: Business Problem
This project is inspired by a new apartment search journey of a friend of mine. It has been a journey that consumed a lot of time and effort for my friend personally and I was thinking it would be nice to have a service that serves normal requirements or special requirements for any of us to search for a new home to settle.
Below are the main factors that would impact my friend’s decision on which area to live or to look for new apartment
- Close distance to work by cycling: My friend loves cycling and he would like to live where it doesn’t take a lot of time in commuting to work place.
- The place is close to shore and has close access to boat places: One of the big hobby is rowing. My friend would love to live in a house where boat docking places are nearby
- House price is affordable: Ofcourse, my friend wants to have the best deal that a place can offer to personal needs including good prices
- Last check points: The neigbourhoods — what it has to offer the new resident
This report is aim to solve an interesting problem for individual needs.
First we will try to define the large areas base on travel distance by bicycling to a specific workplace In this report I will use my friend’s workplace in Helsinki areas as an example and a target for defining travel distances.
After that, we will mark boat docking places in Helsinki Metropolitan area to help targeting a list of neigbourhoods base on postal codes and narrowing down the search.
On top of that, we will visualise the average house prices of each postal code area and find the places/areas which will offer optimal commuting time to work place, close to boat docks and having lowest average price per square meter (m2)
Since we will have the list of promissing postal code areas to look in, we can explore each neigbourhood too see what kind of services it has to offer to normal urban life and provide well defined information so that my friend is will be equipped with data and such has better chance to choose the most suitable new home.
B. Data
Based on definition of our problem, factors that will influence our decission are:
- travel time to the work place: ideal time is 16 minutes one way and the average is 20–30 minutes. My friend prefers something below 25 minutes.
- the availability of boat docks in the neighborhood: the more the merrier
- unit price per square m2 of an apartment : the lower the better
- number of existing restaurants in the neighborhood (any type of restaurants)
Following data sources will be needed to extract/generate the required information:
- coordinate of the work place, which is Pasila in Helsinki center (60.197873, 24.9322653)which is obtained using Nominatim: this data will be the target for calculating travel times.
- spatial data from OpenStreetMap and to visualize, and analyze real-world street networks and calculate travel times.
- location data of the boat docks avaialble in Helsinki metropolitan area (Helsinki, Espoo, Vantaa, and Kauniainen).This data will be used to visualise on map for location of boat docks
- unit price per square meters for houses (all type of houses) in Helsinki metropolitan area. This data will be used to visualise on Chorolepth map the average house price per square meter and it will help to pint point the areas where there are best price.
- location data of postal code areas belong to Helsinki metropolitan area. This data will help to show postal code area on Chorolepth map.
- number of restaurants and their type and location in every neighborhood will be obtained using Foursquare API . This data will be used to explore the neighbourhood of choices after the locations are defined
C. Methodology
We will use K-Means clustering to analyse the data of venues for each neighbourhood we define.
In order to define the optimal k we will use both Elbow and Silhouette Scores methods.
After clustered data we will look closer to each cluster and identify the characteristic of each cluster.
Let’s get to it
1. First , we will need to define the travel zone that will satisfy condition that travel time using bicyle is between 16 and 25 minutes.
We will use network analysis to circle out the areas where it will take less than 25 minutes to cycling to the work place, which is Pasila (60.197873, 24.9322653)
The steps to find travel distance and show it on a map as Travel Time Map
- Identify the center point
- Identify the time that is used for calculation: Here we define 16 minutes as ideal one and 25 minutes as the maximum travel time we can accept
- Find the nodes in the network that can form the areas that fit the time travel — using networkkx library to calculate the travel distance
- Create polygons that represents the border of areas that will take within 16 minutes to travel to work and <25 minutes to travel to work
- Show the result on the map to represent as Travel Time Map.
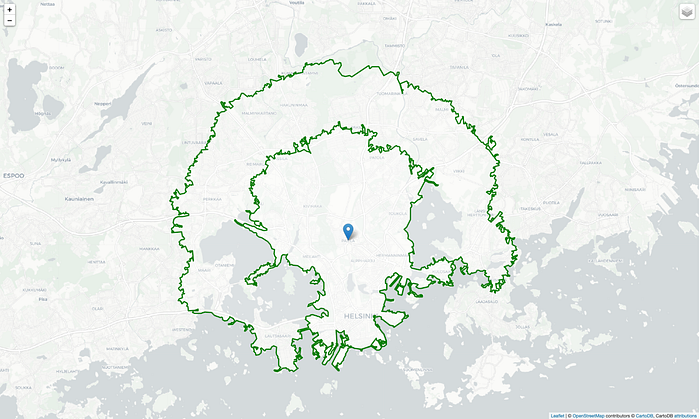
Below is the result of calculation which I created using references from osmx libraries and examples.
Here we defined 2 polygons:
- inner polygon represents the boundary of area that will take ≤ 16 minutes to travel to work place that marked as center point on the map
- outer polygon represents the boundary of area that will take ≤ 25 minutes to travel to work place and it is the maxium acceptable duration as per request by my friend😇
2. As it is an important requirement that the new home will have close access to boat docks. We will need to visualise the location of boat docks and make it easier to pin point which area to look for a new apartment on the map
Data for boat docks:
I could find the infomration about boat docks location from City Service Map of Helsinki: https://palvelukartta.hel.fi/fi/search?q=venesatamat and download the result in JSON format.
Consider the convenient usage of data, I uploaded it to github https://raw.githubusercontent.com/maithoa/Coursera_Capstone/master/data_venesatamat.json
After loaded and cleaned up the data, here is the result we have:

And where they are on the map?
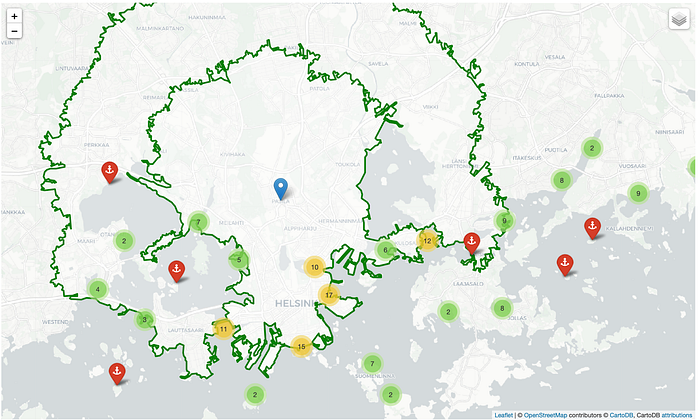
We can see that there are about 15 places that we can look closer, which fit the conditions of optimum travel distance to work palce and have boat docks 🎉
3. Find and Show the price of houses per postal code area on Chorolepth map so that it is easier to identify the areas which best prices
Data for average house prices per postal code areas:
For urban houses unit price per square meter, I get data from Stat.fi service https://pxnet2.stat.fi/PXWeb/pxweb/fi/StatFin/StatFin__asu__ashi__vv/statfin_ashi_pxt_112q.px/ and saved data to an excel file and read the data. Data will have
- posno as “postal code”
- Price_per_m2 to contain price per square meter of the postal code area
- Available_for_sale: to show how many houses are currently on sale
Below is the dataset I have after cleaned up
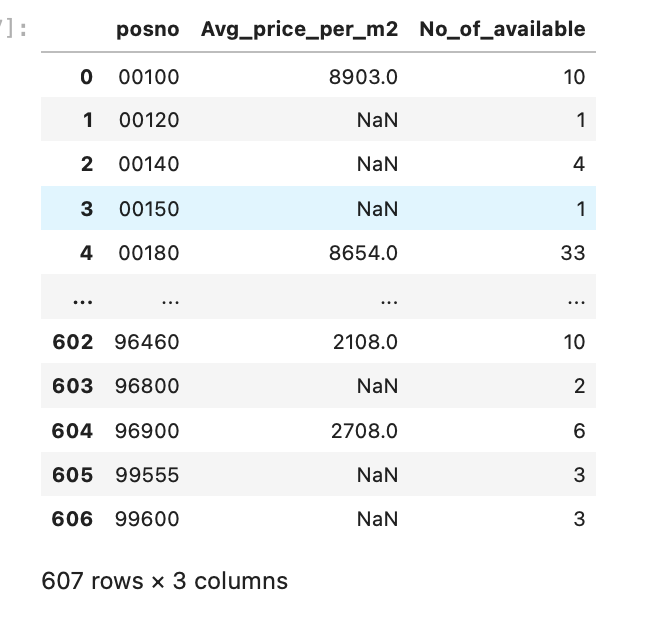
As you can see from the price dataframe, there are some place that has availabe house however the price is not defined. It would be nice to have all prices, however for now we will show what we have. Additionally, we filtered out the postal code areas where there aren’t any houses on sale. The data we have from here contains all postal codes from Finland. Later when we join with location data from Helsinki Metropolitan area, we will have a smaller set of data
Geometry data of postal code areas
We will get geometry data of all postal code areas belong to Helsinki Metropolitan area using webservice wfs_hsy_url = ‘https://kartta.hsy.fi/geoserver/wfs' Data returned by wfs is in gml format. We will use 3rd party tool ogr2ogr to convert gml to geojson
Data we have is in ESPG:3879 coordinates systems so I convert the coordinates to ESPG:4326 so that it can be displayed on Folium map.
Additionally, we will combine the geometry data with house price data using postal code to form the final data set for later display them on a Chorolepth map
Below is the cleaned and combined data set. We also see that the dataset now is smaller. It contains only data of the postal code that belong to Helsinki Metropolitan area

Let’s visualise the average house price per postal code on map
The places that is white are the areas that either doesn’t have any houses on sale or areas that doesn’t have house prices available. We will exclude them from our study.
We can also see that the house are more expensive closer to the work place however there are few candidates in the range of ≤ 25 minutes travel time that we can have a look later.
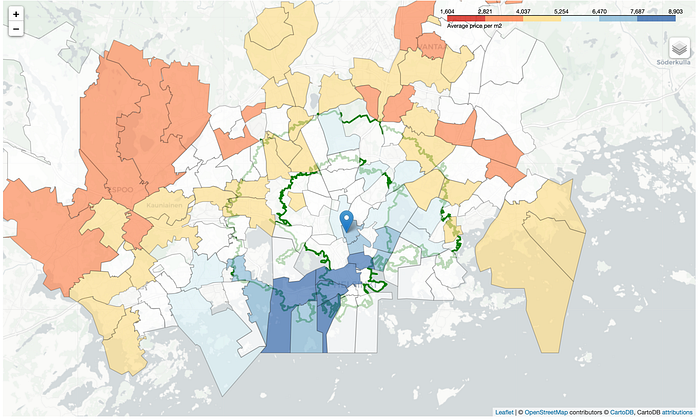
Let’s have the map with also boat places marker
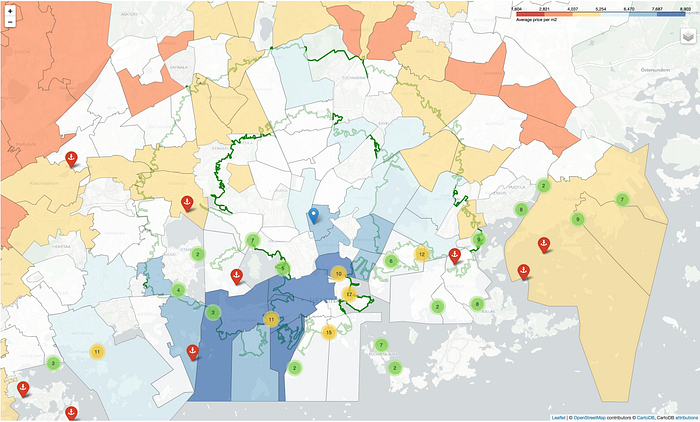
4. Conclusions on the Postal code areas that are potential
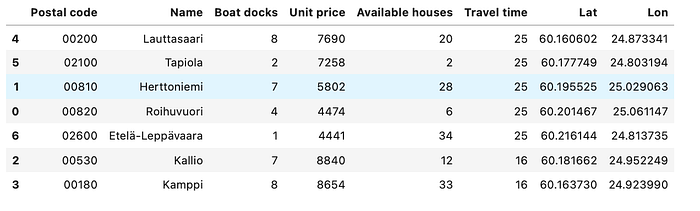
- Roihuvuori — has 4 boat docks and the average price is € 4774 per sqm with 6 available houses — 25mins to work
- Herttoniemi — has 7 boat docks and average price is € 5802 per sqm with 28 available houses — 25 mins to work
- Kallio — has 7 boat docks and average price is € 8840 per sqm and 12 available houses — 16 mins to work
- Kamppi — Ruoholahti — has 8 boat docks and avg price is € 8654 with 33 houses — 16 mins to work
- Lauttasaari — 8 boat docks and avg price is € 7690 with 20 houses — 25 mins to work
- Tapiola — 2 boat docks and avg price is € 7258 with 72 houses- 25 mins to work
- Etelä-Leppävaara — 1 boat dock and avg price is € 4441 with 34 houses — 25 mins to work
We will put the potential areas to a dataframe so that it’s easier to see
Additionally, I use geolocator to find the coordinate of center point of each postal code areas. We will need this information for search more data from Foursquares.
5. Focus on the selected areas and analyse the area what kind of neighbourhood it has
So there are 271 venues that we can get from Foursquares for the selected postal code areas. Let’s group them by Postal code and see if we can describe characteristic of each postal code areas. Below is the a data frame that describe each postal code areas with its top ten popular venues type

6. Analyse the characteristic of the selected postal code areas
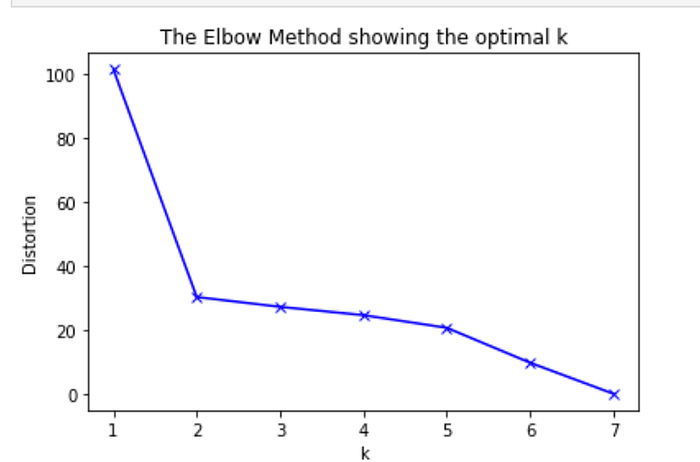
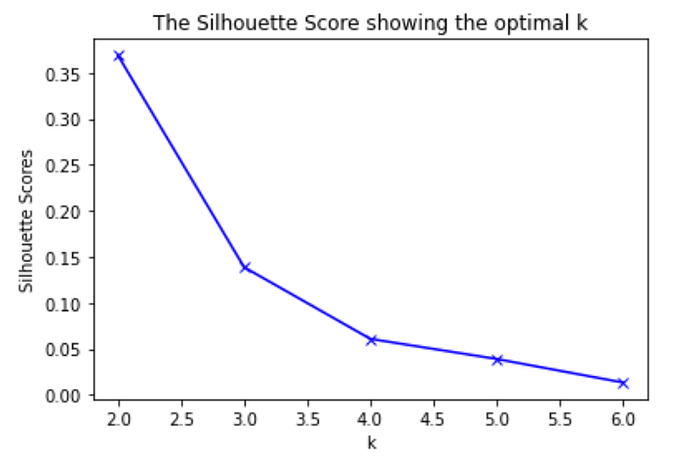
Determine the optimal K value for k-means using Elbow and Silhouette Score method.
Based on the result below I chose k = 2 for clustering the selected postal codes candidates
Examine the clustering results:
Examine Cluster 0

Examine Cluster 1
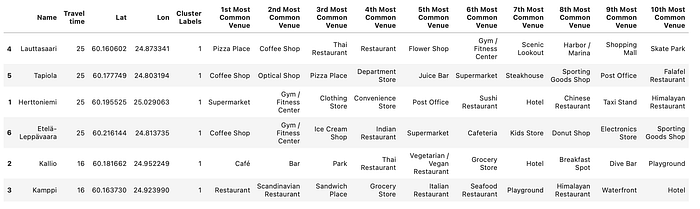
Looks like Roihuvuori doesn’t contain many restaurants and has Parks, Cafe and Grocery stores. While all other places are having richer collection of restaurants to serve the residents in the area.
How about sorting our result data by the order of Unit Price lowest on top, and cluster labels
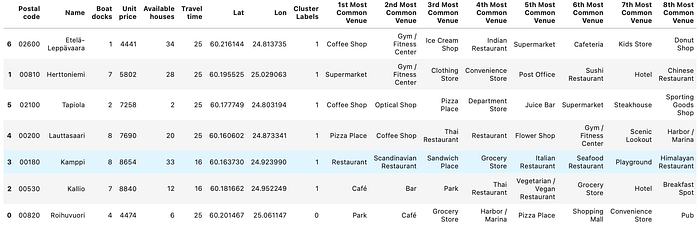
Finally let’s visualise the clustering result of candidate postal code areas on map
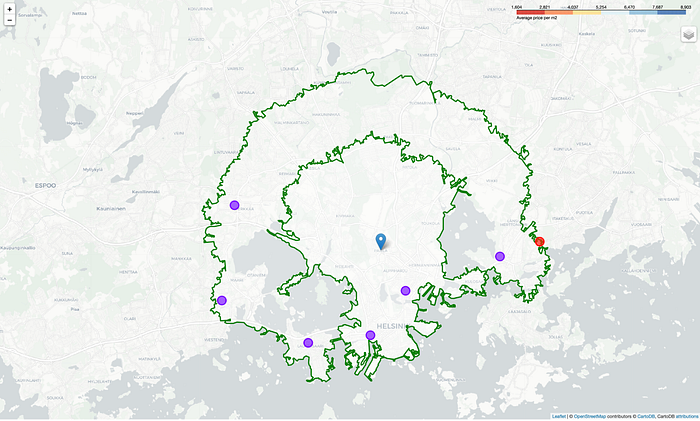
D. Results and Discussion
In our analysis, we are having two strong factors that already limit our focus areas in the search
- Travel time to work place by bicycling : less than 16 min as ideal and less than 25 mins as acceptable duration range
- Availablility of boat docking places. : this is a must
Among the candidate areas that we are able to pick up after narrows the areas down using travel time and boat docking places, by clustering our analysis shows that
- Most of the candidate areas in Cluster 1, which are marked as purple on our cluster map, are offering the residents a variety of places make lives more convenient: Restaurants, Coffee shops, Pizza place, Supermarket or Department stores, Park, Gym or Playground.
- Only one area, Roihuvuori, which is in Cluster 0 and marked as red on our cluster map, is having a limited number of offers and almost no restaurants.
Result of all this is 7 postal code areas that match the main 2 factors with information about average house prices and additional information about what each area has to offer the residents.
Recommended postal codes for my friend to look for new home should therefore be considered only as a starting point for more detailed analysis which could eventually result in location which my friend wants to settle.
E. Conclusions
Purpose of this project is to identify the potential areas for a person to start looking for new home. The areas should provide optimal travel time to work place and near by boat docking places. In addition to that we provide information regarding house prices, neighbourhood analysis for the candidates areas to assist the decision making.
Final decision on optimal new home location will be made by the person based on specific characteristics of neighbourhoods and locations in every recommended postal code area, taking into consideration additional factors like attractiveness of each location (proximity to park or water), real estate availability, type, conditions, prices, social and economic dynamics of every neighbourhood etc.
F. References
- Public Map service of Helsinki for getting boat docks location: https://palvelukartta.hel.fi/fi/search?q=venesatamat
- Public statistic service of Finland to get the housing prices data per postal code area https://pxnet2.stat.fi/PXWeb/pxweb/fi/StatFin/StatFin__asu__ashi__vv/statfin_ashi_pxt_112q.px/
- Web Features service of Helsinki Metropolitan areas to get the geometry of postal code areas https://kartta.hsy.fi/geoserver/wfs
- OSM Network analysis examples to implement the travel times calculation https://github.com/gboeing/osmnx-examples
- My Notebook for this project on Github: https://github.com/maithoa/Coursera_Capstone/blob/master/Week5.ipynb
Thank you for reading 🍀🙏
